
When the web was growing up, it hit a phase where we didn't want to just read stuff on the web we wanted to be able to interact - we wanted our say. At the time this was called web 2.0. Suddenly websites would let you put your words on them without touching a line of html. Us lazy humans however wanted our say NOW! we didn't want to wait for a page to reload so we could see it, we wanted it to appear instantly without refreshing the page. "It is essential that you know my thoughts on the Arctic Monkeys 2006".
The technology AJAX (Asynchronous Javascript and XML) made this possible. Javascript would run in your browser and communicate with the server in the background all the while you never had to leave the page.
The backbone of this is the XMLHttpRequest, which Microsoft developed that quickly became the standard.
Luckily for us today, this is still around - we can use it to our advantage when we want to scrape a website. Yay!
Developer Tools
Open up the developer tools in your browser, go to the 'network' tab and then click on 'xhr'
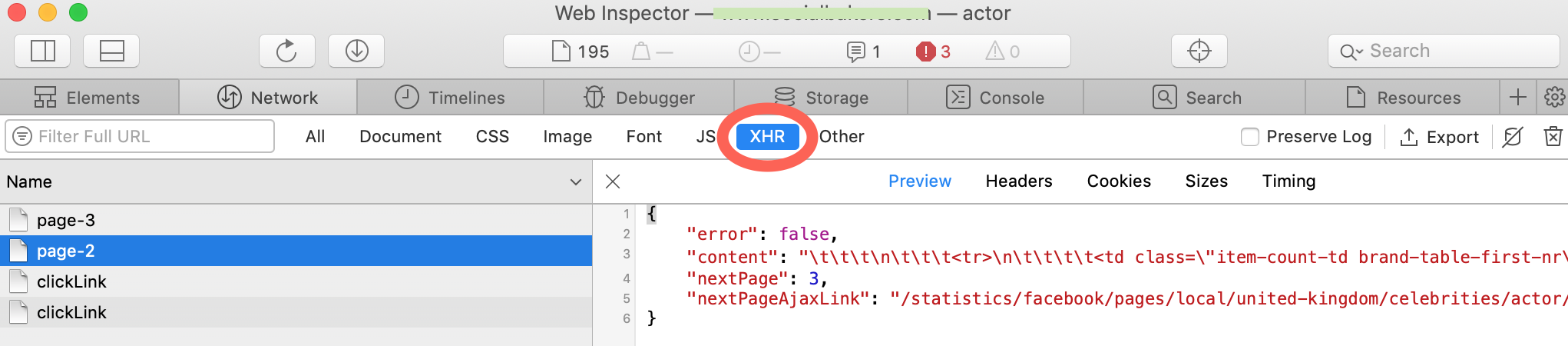
We can see that a page-2 was requested, and a json file is returned. The bit we are interested in is the "content" key in that json file. It also helps us that there is a nextPageAjaxLink, we can tell our script to keep following these links to load the next data, but this (or it's equivalent) won't always be there.
The text within the "content" key looks like html, so we can parse that nice and quickly with BeautifulSoup, save the details and load the next.
It's important to look at the headers here too, as the site may require a few extra bits of information in the header in order to return the requested object to you. The important info is in the Request section:

When you request the next page, you'll need to use some of this information. The requests module makes this nice and easy for us. Take note of the pattern of what you'll need to replace in the example above. You'll need to note that the authority and host are the root of the site e.g. www.example.com.
Note that the page number is an argument in the path "..../actor/page-2/" - perfect opportunity for an f-string: f"page-{page_number}"
Using this in your code
You should end up with a dictionary that looks like this:
headers = {"method":"GET",
"scheme":"https",
"authority":"www.example.com",
...
"X-Requested-With": "XMLHttpRequest"}It's worth leaving put the "Accept-Encoding" element as BeautifulSoup doesn't play nicely with a gzipped response.
Now you have that part down, you can get ready to call the pages in a loop:
for page_number in range(10):
url = f"ht........./actor/page-{page_number}/......"
headers = {"method":"GET",
"scheme":"https",
"authority":"www.example.com",
"path":f"........./actor/page-{page_number}/......",
...
"X-Requested-With": "XMLHttpRequest"}
r = requests.get(url, headers = headers)
soup = BeautifulSoup(r.json()['content'], 'html.parser')Remember to scrape responsiby, and be sure to check out a websites robots.txt file and TOS before you get that sweet, sweet data.
Comments