
Continued from Part One
Right so you have done a bunch of scraping, and now you have a lot of data. sweet let's get our feet up and chill.
Wrong, you're summoned back in to the boss.
You could have scraped that data a bit quicker, but whatever. Now I need you to do some analysis on that data, here's what we want to look at:
- What components of a job posting distinguish data scientists from other data jobs?
- What features are important for distinguishing junior vs. senior positions?
- Do the requirements for titles vary significantly with industry (e.g. healthcare vs. government)?
It would be excellent if we could get these answers straight away, but our data is nowhere near up to snuff.
Pandas
There's a real handy library for dealing with lots of data all at once, its called Pandas. Pandas allows us to load our dictionary of values from the scrape into an object called a Data Frame. We can think of the dataframe like a sheet in excel, but a lot more versatile, it makes our lives a lot easier by making a lot of functions readily accessible. The first thing we are going to do is to save the data from memory to our hard drive, then we can breathe a lot easier.
import pandas as pd
#Create a dataframe from our results
df = pd.DataFrame(data=results)
#save the data to a .csv file
df.to_csv('indeed_scrape.csv')From here, we will interact with the data in our dataframe 'df'
When we ran the scrape, if a feature wasn't present in the listing, we kept a string, for example saying "No Salary". Unfortunately if we want to be predicting a salary, or salary range, we have no way of using the listing to build a model on. We are going to have to remove these rows from our dataframe.
df = df[df.salary != "No Salary"]We can see that the salary postings vary quite a lot by city and after scraping so many pages, we have relatively few results.
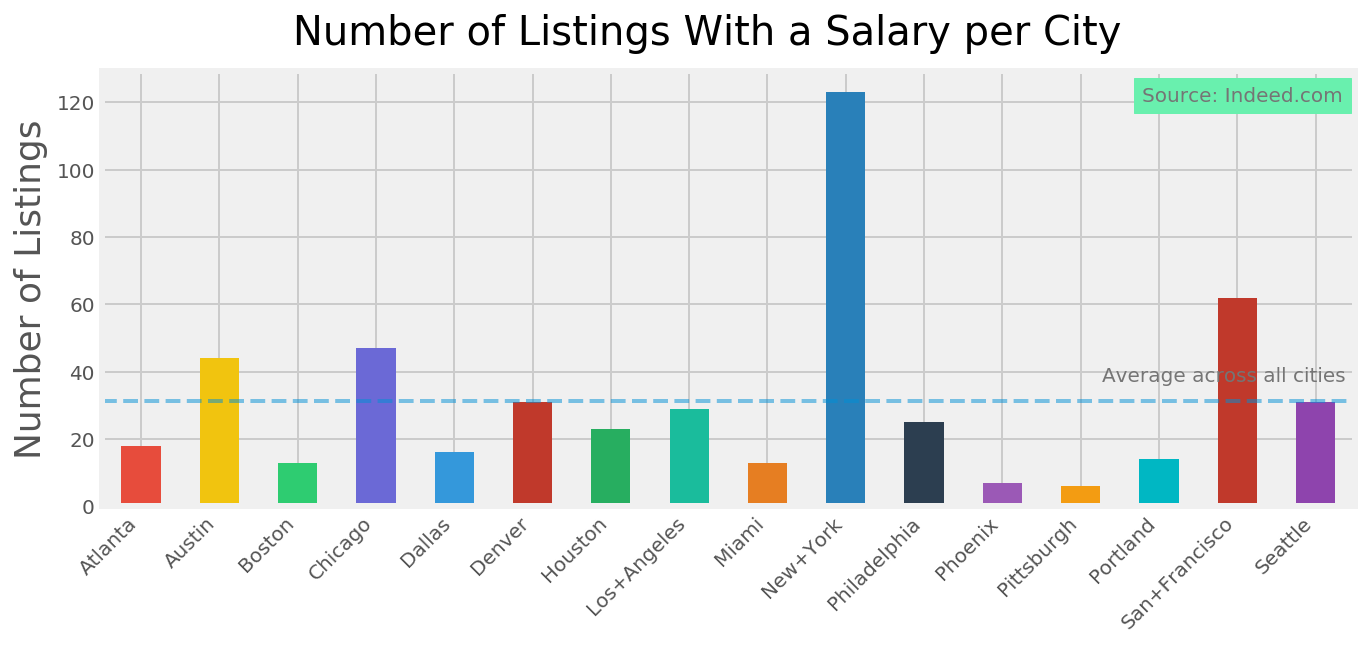
So for us to do anything with the salary information, we are going to need to remove any extraneous information, only keeping the numerical data. We see that most of the values indicate a range, and some break the range down by day, month or year, so we are going to have to fix that too.
Before we get rid of the extra info, we can keep some indicators in new columns, e.g. daily, monthly, yearly. We'll use a lambda function here, but for the time being we won't delve into them too much.
df['yearly'] = df['salary'].map(lambda x: 1 if 'year' in x.lower() else 0)
df['monthly'] = df['salary'].map(lambda x: 1 if 'month' in x.lower() else 0)
df['hourly'] = df['salary'].map(lambda x: 1 if 'hour' in x.lower() else 0)Aside note, the javascript I use to highlight code is removing dollar symbols, it also looks to be duplicating chunks
def string_to_salary(x):
#check if the salary is already correctly formatted
if type(x) == int:
return x
#Check if salary given as yearly
elif 'a year' in str(x).lower():
# check if salary given as a range
if '-' in str(x):
# remove dollar signs from string
x.replace("$", '')
#find only the digits and commas
nums = re.findall('[\d,]+', x)
sum_ = 0
#for each digit with comma separator, replace the comma
for num in nums:
#keep a track of the sum of the salary range
sum_ += int(num.replace(',', ''))
#return average of salary range
return (sum_/len(nums))
else:
# remove dollar signs from string
x.replace("$", '')
#find only the digits and commas
num = re.findall('[\d,]+', x)
return float(num[0].replace(",",""))
#check if salary is monthly
elif 'a month' in str(x).lower():
# check if salary given as a range
if '-' in str(x):
# remove dollar signs from string
x.replace("$", '')
nums = re.findall('[\d,]+', x)
sum_ = 0
#for each digit with comma separator, replace the comma
for num in nums:
#keep a track of the sum of the salary range
sum_ += int(num.replace(',', ''))
#return average of salary range multiply by 12 for months
return (sum_/len(nums)) * 12
else:
# remove dollar signs from string
x.replace("$", '')
#find only the digits and commas
num = re.findall('[\d,]+', x)
#multiply rate by 12 for months in year
return float(num[0].replace(",","")) * 12
#check if salary is hourly
elif 'an hour' in str(x).lower():
# check if salary given as a range
if '-' in str(x):
# remove dollar signs from string
x.replace("$", '')
#find only the digits and decimal places
nums = re.findall('[\d.]+', x)
sum_ = 0
for num in nums:
sum_ += float(num)
return sum_/len(nums) * 2000
else:
x.replace("$", '')
#find only the digits and decimal places
nums = re.findall('[\d.]+', x)
sum_ = 0
for num in nums:
sum_ += float(num.strip())
#return average of salary range
return sum_ * 2000
Then we will apply this function to the salary column. We use the map function that Pandas helpfully provides. This allows us to use the function on every cell in the column.
df['real_salary'] = df['salary'].map(string_to_salary)Great - from here we can properly look at things. Let's have a look at the average salary per city:
fig, ax = plt.subplots(figsize=(10, 4))
df[df.real_salary > 0].groupby('city').mean().plot(
kind='bar', y='real_salary', ax=ax, color=colours)
fig.suptitle("Average Salary per City", fontsize=20,)
ax.axhline(y = df.real_salary.mean(),ls='dashed',
linewidth=2,alpha=0.5,label='All Cities Average')
ax.legend_.remove()
ax.set_ylabel('Maximum Salary ($)',fontsize=18)
ax.set_xlabel('City',fontsize=18)
plt.xticks(rotation=45,ha='right')
ax.annotate('Source: Indeed.com', (0, 0), (520, -70),
xycoords='axes fraction', textcoords='offset points',
va='top', fontsize=10, color='#757575',
backgroundcolor='#69F0AE')
plt.show()
Now we have some useful data, we can probably get our feet up.
Comments