
Picture the following scenario:
Its 9:05 on Monday morning, and no sooner has your preferred caffeine delivery liquid been poured (tea, white and 1 if you are asking) than your boss calls you in for a quick one on one..
I'm going to need you to do some scraping, and I have a very specific set of hoops you need to jump through they say..
- I need yo to scrape job listings on the indeed.com website
- You need to scrape from 16 cities worth of listings
- You will do the scraping from within an ipython notebook.You will use the requests library to get the web page you want to scrape. You must use the BeautifulSoup library to parse the html.
- You will scrape only 4 fields of data per job post.
- You will store the results in a dataframe.
Why are you telling me to look at job hunting sites on a Monday morning you think to yourself?
Sure, you say, you got it boss.
Best get our notebook fired up and off we go.
import requests
from bs4 import BeautifulSoup
Indeed.com
We've checked the indeed robots.txt and there's no rules against scraping the returned search pages. Great, they must have expected us.
Esch Job Listing looks like the below:
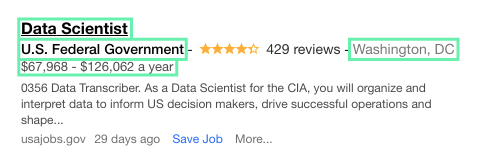
The bits we want out of them are the bits I have boxed:
- Location
- Title
- Salary
- Company
We're going to keep a dictionary of all the results, and as we go through each search page, we will add more results to the dictionary and then move on to the next page. We'll use a dictionary as this allows us to keep all the info in an easy to access way later on.
Beautiful Soup
Lets build some functions using BeautifulSoup to parse out the bits we want, We'll make 4 functions, one for each bit of information. Here's how we will take out the information for the company:
We have established the html for the page we want to look at by visiting the page in our web browser, hovering over the text we are interested in, right clicking, and choosing 'inspect element'
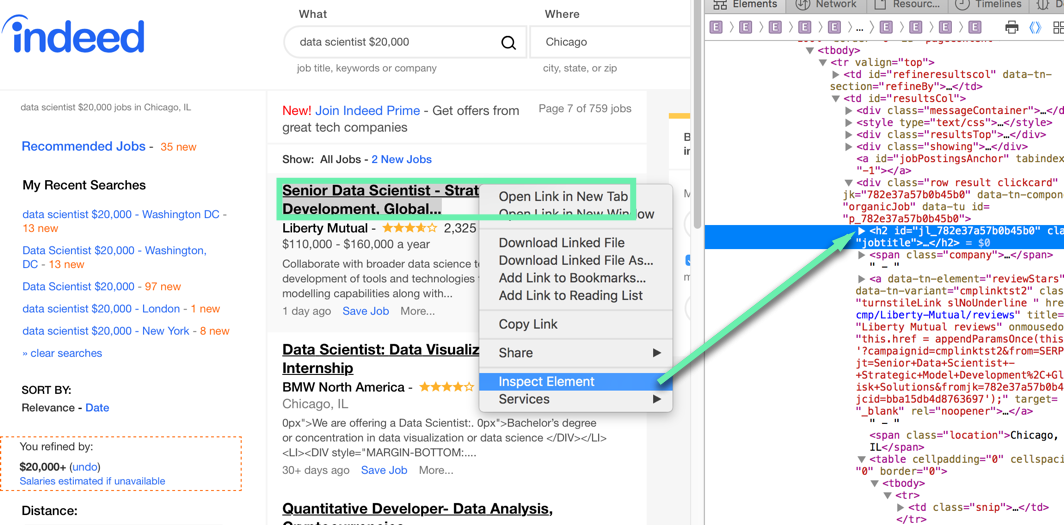
We can see that the text we are after is tucked away under a span tag, with the class 'company'. If we want to get this with BeautifulSoup we will have to do something like this:
def extract_company_from_soup(soup):
# create a list to keep company names in
companies = []
# find all span tags with class 'company'
for c in soup.find_all("span", class_="company"):
# take the text from within the tag
company = c.get_text()
if company == "" or company ==None:
# if there's no company info, record this
company = "No Company"
else:
# replace the blank spaces at the start of the company string
company = re.sub('^\s+','',company)
# if the company only had white space, recored this
if len(company) == 0:
company = "No Company"
# add the name of the company to our list of companies
companies.append(company)
#return the list of companies from one page of searching
return companies
Once we have done this for each element we want to keep, we can add the results to our master dictionary. We will have 4 lists per results page, one list for each feature. We are also going to keep the city that we used in the search bar, just to help us
titles = extract_title_from_soup(soup)
salaries = extract_salary_from_soup(soup)
companies = extract_company_from_soup(soup)
locations = extract_location_from_soup(soup)
"""we need to check that there are the same number of entires in each list
otherwise our index will be all over the show."""
if len(titles) == len(salaries) == len(companies) == len(locations):
"""also keep a record of the city
we searched for to get these results"""
results['city'].extend( [city] * len(locations))
results['location'].extend(locations)
results['title'].extend(titles)
results['company'].extend(companies)
results['salary'].extend(salaries)
Now we have our methods set up to get the info, let's loop through each city, and through the number of results we want to scrape, saving each page's worth of results to the dictionary as we go.
The dictionary will also make things a lot easier to turn into a data frame as required.
We can deal with cleaning up the results tomorrow.
Comments